2010-04-22
Direct2D: Investigating Cached Tessellations
So, at Mozilla we've been looking into more ways to improve our performance in the area of complex graphics. One area where Direct2D is currently not giving us the kind of improvements we'd like, is in the case of drawing complex paths. The problem is that drawing paths will re-analyze the path on every frame using the CPU, causing these scenarios to be bound mainly by the speed of the CPU. This is something we'd like to address in order to improve performance of for example dynamic SVG images, after all once you have analyzed a certain path once, you want to retain as much as you can from that analysis, and re-use it when drawing a new frame with only small changes.
Path Retention Support in Cairo
One of the things that needs to happen is we need to support retaining paths in cairo, in such a way that a cairo surface can choose to associate and retain backend specific data related to that path. Much like is already possible in cairo for surface structures. That is a task which has been taken up by Matt Woodrow and has been coming along nicely (see bug 555877) and I'm not going to spend a lot of time talking about this. What I am going to talk about is my investigation into how to put this to good use from a Direct2D perspective.
Tessellation Caching in Direct2D
When I started my investigation, I was hoping that perhaps ID2D1Geometry would have some level of internal caching. In other words, if I'd just fill the same ID2D1Geometry every frame, this would be significantly faster than re-creating the geometry each frame. For testing this I chose the following geometry, the geometry I chose here is fairly simple, but it has some intersections and some nice big curves, so tessellation should be non-trivial:
sink->BeginFigure(D2D1::Point2F(600, 200), D2D1_FIGURE_BEGIN_FILLED);
D2D1_BEZIER_SEGMENT seg[3];
seg[0].point1 = D2D1::Point2F(1100, 200);
seg[0].point2 = D2D1::Point2F(1100, 700);
seg[0].point3 = D2D1::Point2F(600, 700);
seg[1].point1 = D2D1::Point2F(100, 700);
seg[1].point2 = D2D1::Point2F(100, 200);
seg[1].point3 = D2D1::Point2F(600, 200);
seg[2].point1 = D2D1::Point2F(1400, 300);
seg[2].point2 = D2D1::Point2F(1400, 1400);
seg[2].point3 = D2D1::Point2F(600, 1000);
sink->AddBeziers(seg, 3);
sink->AddLine(D2D1::Point2F(30, 130));
sink->EndFigure(D2D1_FIGURE_END_CLOSED);
Sadly there seemed to be no caching going on, the only speed improvement I could see was from not creating the geometry, the actual rendering showed no performance benefits. However, as we are determined to see if it is possible to do something else to get the desired effect, our eye was caught by another D2D interface.
The ID2D1Mesh and its limitations
So Direct2D has a Mesh object, this is a device dependent object which can be created on a render target, and then filled with the tessellation of an existing geometry (with a certain transformation applied). I should note here that since this Mesh is a collection of triangles, the level of detail is determined by the transformation passed into Tessellate. This means that if you simply zoom in on the mesh, at some point curves will no longer be curves. This is the first limitation of Meshes, however for the purposes of this investigation I'm going to assume we will not scale and I'm simply going to be drawing the same untransformed geometry over and over again. In any case, more often than not we won't be scaling up significantly, and this isn't really a limitation, it just means we have to re-tessellate in some cases.
Now there's another limitation which is more problematic, Meshes only work with Direct2D render targets which have Per Primitive Anti-Aliasing disabled (From here on PPAA). PPAA is an analytical anti-aliasing routine, which is most likely part of the reason why tessellations are not cached by Geometries internally. Anti-Aliasing is important to us, non-AA drawing in Mozilla is rare, and without it things would truly not look so good! There is another option though, when drawing to DXGI surfaces, as we do, you can set the GPU to use Multi-Sample Anti-Aliasing(From here on MSAA) to do anti-aliasing.
MSAA vs. PPAA
So, quality of MSAA is worse than that of PPAA, however it is also faster than PPAA on decent graphics hardware. But we'll get to analyzing the performance of several different solutions later, let's see about the quality. First of all, with no scaling:
 |  |
Now for a bit more detail:
 |  |
Notice the smoother transition from white to red on the left edge in the PPAA version. So there's most certainly a difference in quality, although MSAA isn't that bad either! (On some hardware it may be higher or lower quality due to hardware MSAA capabilities)
Another Limitation of MSAA
So at this point, we would be about ready to see about performance differences, except for one thing: MSAA is no longer used when you use PushLayer! The intermediate surface that gets created with PushLayer appears to not inherit the original surface's MSAA settings. Since we use Layers in order to do geometric clipping this poses another problem. We need to be able to do geometric clipping, while continuing to use our retained mesh, and with MSAA. To overcome this method in my investigation I've optionally used another method of clipping, I've created a texture with MSAA enabled (much like CreateLayer), and then I've created a non-MSAA texture, around which a SharedBitmap was created (so that it can be drawn to the main render target). When clipping, the geometry would be drawn to the MSAA texture, which could then be resolved to the non-MSAA texture, which was drawn into the clipping area using FillGeometry. The clipping area was chosen to be a single triangle, non-rectangular as to prevent any optimizations using scissor rects, but also to be trivial to tessellate so that the FillGeometry call for the clipping would not poison the measurement (optionally we could use FillMesh for the clipping area as well using this approach if we had a complex clipping path!)
Testing Conditions
- Core i7 920
- ATI Radeon HD5850
- Stand-alone skeleton D2D application
- MSAA x8 where MSAA is specified
- Surface 1460x760 pixels
- Drawn 100 times per frame
- 10 draws per clip where clipping is enabled
- All D3D multithreaded optimizations disabled
- Rendering as often as possible, no VSync, clearing once per frame
- No Mesh Measurements with PPAA (since it doesn't work)
CPU Usage
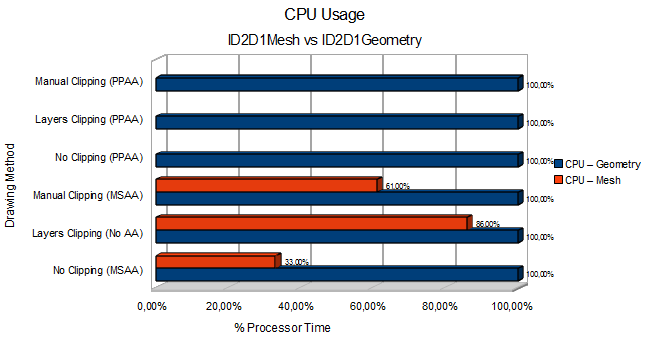
As we can see there's a very consistent pattern: The CPU is consistently saturated for drawing the Geometry without cached tessellation. When we draw our existing Mesh, we can see a significant reduction in CPU usage and we supposedly become GPU bound.
Rendering Speed
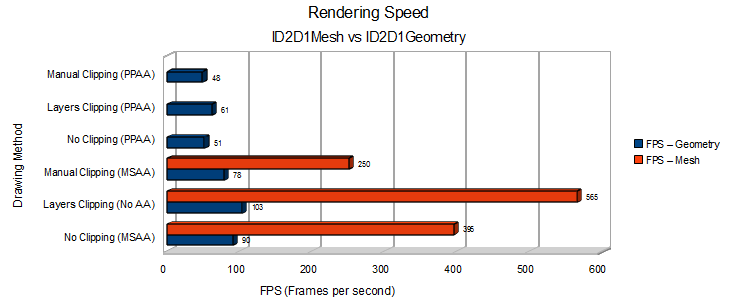
We can see that using the retained tessellation through a ID2D1Mesh can offer a significant performance benefit over using an ID2D1Geometry. Also note that drawing to a clipping layer appears to be somewhat faster than drawing to the backbuffer surface directly.
What do we see?
So these are the numbers. The cause of drawing to a clipping layer being slightly faster is most likely that a DXGI surface render target needs to do some degree of syncing that an internal D2D render target (created by PushLayer) does not.
We can clearly see that we can free up a lot of CPU when retaining tessellations of some complexity, even while we produce higher framerates.
One thing I've noticed is that BeginDraw and EndDraw take a lot of CPU, not doing these calls when using the intermediate clipping render target seemed to significantly reduce CPU usage (although of course the results are no longer guaranteed to be correct since EndDraw ensures that all rendering commands are flushed, hence this method wasn't used). Additionally using Flush on the render target rather than EndDraw before resolving the MSAA surface (which should in theory produce correct results) seemed to also lower the CPU usage by some degree, however due to the correctness being hard to judge in these cases I chose not to do the latter either. However there is room for further analysis here and perhaps an even further decrease of CPU usage in the Mesh rendering with manual clipping approach.
Any Conclusion?
Well, I can't really draw any conclusions from this at this point, there's a clear trade-off between performance and quality. It's certainly worth investigating further and possibly a 'mixed' approach could be used depending on the complexity of the path and quality requirements of the user. I realize this was a pretty long and technical post :) But I hope that for those of you interested in this sort of stuff I've been able to provide some interesting initial measurements in the area of complex geometry rendering in Direct2D. I'm looking forward to any opinions, criticisms, hints or other form of input on my methods and ideas!
13 comments
My main concern is that the machine you use to make measurements is a tad unrealistic. Even if you take http://store.steampowered.com/hwsurvey/ (and that’s a gamer’s survey!) the vast majority of the cards are less than half as fast as the beast you use. On the notebook market (unfortunately) integrated “solutions” rule, and I have a feeling they won’t perform MSAA as happily as an high-end desktop card (MPAA in Fx D2D and in IE9 preview works fine and even these cards are very useful compared with the CPU).
MSAA performance varies greatly between cards, and there can be some pitfalls (i.e. fast until 4x, then 8x halves performance because it’s implemented as two passes).
OTOH while your CPU is also too fast, there’s much less variation in the CPU world, which means your average machine will have a relatively faster CPU and slower GPU.
So I’d grab a crappy notebook with Intel graphics (X3100 or newer, on Windows 7 - all of these support DirectX10 and are more or less the same hardware at varying speeds) just to make sure it’s reasonable. Also some nVidia card (which still are majority).
Thanks for your work!
@Dan: I do agree! The main point of the exercise was to see how much we could offload the CPU though, so a fast GPU was alright.
But yes, I share your concern although I believe more or less by design DX10 cards should do MSAA fairly well up to 4x usually. But I haven’t tested on low-end hardware. I agree that it’s definitely something to look into.
However note that it would be okay to be more GPU limited. We don’t need 300 fps, but for many other tasks in mozilla freeing up the CPU is very valuable. Of course if it would become an unworkably low framerate that’s another situation :).
You could of course skip the tessellation stage altogether ;)
@robert: That is an interesting read :-). Since the linked article detailing the technique is from Microsoft Research one might wonder if Direct2D uses any of this internally ;).
http://www.jesperjuul.net/ludologist/?p=1030 this is an interesting way i believe.but before this can be used microsoft need to fix the bug related to this .bitmap went from 39 fps to 590 fps(java)
but like the link on ther bottom of the page say sun wont move till microsoft fix their bug.so this idea is a nono.unless you have connection to microsoft to make them fix this bug(that would be nice)
Have you tried FillOpacityMask? You can draw the geometry into a CompatibleRenderTarget with the A8 pixel format, get the D2D Bitmap representing the coverage of the geometry rendering and then use it as an input to FillOpacityMask.
If you’re drawing geometries that don’t animate, this may be what you’re looking for.
http://msdn.microsoft.com/en-us/library/dd372260(v=VS.85).aspx#staticContent
Hello
http://braid-game.com/news/?p=455
http://braid-game.com/news/?p=466 I came across this blog stating why direct2d is redundant and also not that great. Braid hopes that the direct2d api does not take off because of such issues.
” The Direct3D version does not need to allocate permanent resources that would need to be tracked, destroyed on a reset, etc. “
I am not a programmer but this sounds similar to the issue of “The problem is that drawing paths will re-analyze the path on every frame using the CPU, causing these scenarios to be bound mainly by the speed of the CPU.”
So maybe there is a way to leverage direct3d 9 so that it will be easier to support the existing 60% XP share as well as the 20% Vista+7.
@J:
Well, not quite. First of all, Braid is wrong, he’s right in the sense that drawing a pixel aligned rectangle is easier in D3D. His article leads me to believe he has -no- idea what he’s talking about whatsoever.
He’s wrong in the sense that first of all, D2D offers you a lot of things which are very -hard- to do in D3D. They’re certainly possible, but just very hard. Tessellation is a very complex task especially as Geometry gets more complex. This is the major point where D2D shines, it’s got a great tessellator, I’d like the author of the article to fill the outline of a bunny with a gradient (vector graphics wise!) with just D3D, then we’ll compare codesizes. Direct2D wasn’t made for drawing rectangles and gridlines, really.
Second, reference counting and object retention isn’t inherently bad. If OpenGL had such features it would make my job a lot easier :-). If you’re hobby-ing on your little 5000 lines of code space invaders game, sure, it’s more than you need, but not using it is fairly trivial (just Release once instead of delete, and don’t use smart pointers or add references, etc, this is actually required anyway since you can’t use delete for objects created across a library boundary).
The re-analysis Direct2D is inherently required to do the high anti aliasing quality level that they provide. Their documentation stated quite clearly my approach mentioned above for using MSAA is also valid, just lower quality, that’s what this post is about.
Certainly Direct2D has its weaknesses, none of its true weaknesses are described in the aforementioned article though. In the long run this may mean we’ll do something with Direct3D 10. As for Direct3D9, we’re supporting it for layers. However, given the amount of time it will take us to write a vector graphics renderer on top of Direct3D9 this is not very useful - by then XP market share will have dropped significantly.
I’d love to see the comparison vs. the A8 technique that Bob pointed out.
details:
http://msdn.microsoft.com/en-us/library/dd756659(v=VS.85).aspx
I don’t think MSAA is practical for an app like firefox.
1) the quality isn’t acceptable until you use at least 8x MSAA…even then it’s worse as you pointed out.
2) MSAA takes at least 8 times the memory for the frame buffer. This is HUGE!
It’s quite common to have at least 1080p resolutions & FF maximized. So for a single instance of FF and only a single framebuffer (no layers) you use almost 70MB of memory! (1920*1080*4*8) Seems like a deal breaker.
@Brandon:
First of all, the A8 technique is not very feasible for us, due to the amount of paths we have this would have terrible memory implications.
It’s true, there’s memory bandwidth and shader implications for MSAA. It doesn’t ‘just’ use 8 times the memory though like SSAA does. So there might actually be cases where we can live with it, but it’s tricky.
@Bas,
Can you link me information on how MSAA uses less memory? I’ve found several conflicting accounts online of exactly how it’s implemented.
My understanding is that it uses the same memory as SSAA, but saves bandwidth & processing because it only evaluates shaders once per pixel (instead of once per subpixel like SSAA).
Reference:
http://www.devmaster.net/wiki/Multisampling
In the case that the coverage is 100% it can save bandwidth by not writing to all 8 samples (just write the color once & have a flag saying which samples it covers), but I’ve never heard of an optimization that didn’t require the memory to be available in case 8 triangles meet on a single pixel.
On ’tiled’ GPU’s it can obviously use less memory because only one tile needs to be 8x as big. Most desktop GPU’s aren’t tiled though.
@Bas
You may be right about A8 (which is why the comparison would be nice :) but I not sure if the memory consumption would be as terrible as you think (compared to MSAA).
Speculation/Assumptions:
Most of the shapes are probably fairly trivial (rectangles & simple paths), and may not benifit from caching optimizations - just let them be tesselated.
You only need to cache non-dynamic shapes that are deemed complex based on some heuristic (like the curvy-self intersecting shape in your example above).
If my numbers above are accurate, then not using MSAA will save ~60MB. So for the same memory consumption you could cache ~30 full-screen (1080p) A8 surfaces. Most shapes aren’t going to be full screen so you can atlas them. That’s works out to nearly 900 cached complex shapes if we assume an average size of 256x256 (bigger than your complex shape above).
I don’t have numbers on the statistics for the expected #/size of complex shapes on webpages but the break even point seems pretty reasonable if I haven’t made a mistake in my calculations.
Another benifit is that it’s more pay-for-play compared to MSAA which always uses the memory AFAIK.
@Brandon:
I’ll ask the guys at NVidia about MSAA next time I talk to them. As far as I know MSAA is a very broad term and encompasses a whole bunch of antialiasing techniques that aren’t simple full scene AA. I don’t think there’s a ‘this is how MSAA’ works definition. I believe, and again, I might be wrong, that for a general case in the desktop GPU there is significantly increased memory usage for the framebuffer, but I don’t know at what point the sampling occurs and what tricks might be applied to reduce that (I’m sure these guys are full of tricks).
The A8 technique has another issue though, which is I’m not sure how correct the antialiasing is under things like rotations and such. The sample in the SDK looks relatively poor quality under a rotation at the primitive edges (easily good enough for a game, not so much for a webbrowser).
The other concern is that with MSAA, the additional memory usage is constant, whereas with A8 surface caching we’ll need some forms of heuristic. We can’t have a certain SVG certainly take 600 MB of VRAM since the guy who rote them decided to do 200 fullscreen paths with some nasty beziers. It’s a fairly complicated problem but the first thing that would have to be looked into is correctness and quality. Correctness is for us more important than performance in the general case.